
Trích rút từ khóa là một trong những phương pháp đơn giản nhất giúp cho việc phân tích & khai thác các giá trị từ dữ liệu văn bản. Bài toán trích rút từ khóa (tiếng anh: Keyword Extraction hoặc Keyphare Extraction) là quá trình tự động trích rút ra các từ khóa/ thuật ngữ […]
#nlp
Phân loại văn bản tiếng Việt sử dụng machine learning
Phân loại văn bản (Text classification) là một bài toán phổ biến trong xử lý ngôn ngữ tự nhiên (Nature language processing). Đối với phân loại văn bản tiếng Việt, sẽ có đôi chút khác biệt so với phân loại văn bản tiếng anh. Trong bài viết này, Lập Trình Không Khó (LTKK) sẽ hướng […]
Beam search là gì? Vai trò của beam search trong NLP
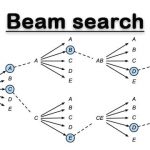
Thuật toán beam search là một thuật toán tìm kiếm heuristic. Nó được sử dụng trong các bài toán như dịch máy, nhận dạng giọng nói, tóm tắt văn bản,… Đó là các bài toán NLP có đầu ra liên quan đến việc tạo một chuỗi các từ. Trong bài viết này, LTKK sẽ cùng […]
Xử lý tiếng Việt trong Python

Trong bài chia sẻ này, Lập Trình Không Khó sẽ trình bày một số kiến thức liên quan tới việc xử lý tiếng Việt trong Python phục vụ cho các bài toán liên quan đến dữ liệu tiếng Việt (có dấu), đặc biệt là các bài toán trong lĩnh vực xử lý ngôn ngữ tự […]
Xóa dấu tiếng Việt trong Java, JS, Python

Trong quá trình triển khai các dự án, đôi khi bạn muốn xóa dấu tiếng việt của một câu văn bản bất kỳ. Chẳng hạn một bài toán đơn giản là bài toán tạo url cho bài viết từ tiêu đề của bài viết. Trong bài này mình xin chia sẻ một số cách đơn […]